Vor Kurzem fragte ich mich, wie man wohl die Verteilungsfunktionen des Produktes zweier unabhängiger Zufallsvariablen bestimmen könne. Nachdem die Internetrecherchen nicht viel hergaben, musste ich meinen Hirnschmalz zusammennehmen… und meine Erkenntnisse mit euch teilen 🙂
Allgemeiner Fall
An sich ist die Berechnung ganz einfach. Man möge einfach die entstehende Zufallsvariable 





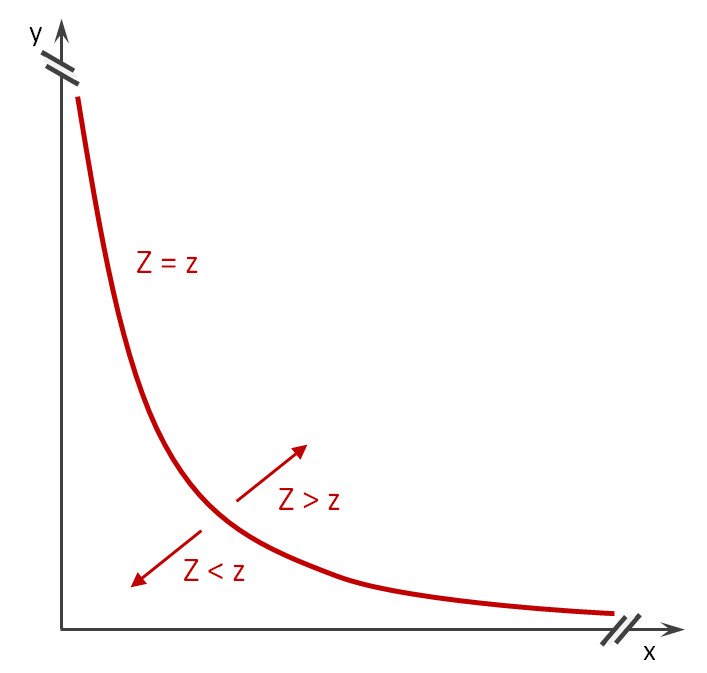
Für alle denkbaren Werte von Z ergibt sich eine Kurvenschar, welche die Paarung möglicher Faktoren beschreibt.
Man müsste nun nur die Wahrscheinlichkeiten ")
")
Wir können problemlos die kumulative Wahrscheinlichlichkeitsfunktion bestimmen, wenn für jedes 
=P\big(z \leq Z)= \int\limits_{- \infty}^{\infty} \int\limits_{0}^{\frac{z}{x}} g_{x,y}\big( x,y \big) \, dy \, dx")
Da
= \int\limits_{- \infty}^{\infty} g_{x}\big( x \big) \int\limits_{0}^{\frac{z}{x}} g_{y}\big(y \big) \, dy \, dx")
Aus der kumulativen Wahrscheinlichkeitsfunktion wiederrum, können wir die Wahrscheinlichkeitsdichtefunktion ermitteln. Diese lässt sich definitionsgemäß durch Ableiten bestimmen.
=\frac{d\big (F_{z} \big )}{dz}")
Beispiel anhand gleichverteilter Zufallsvariablen
Schauen wir uns ein Beispiel an, bei dem 
=1/100")
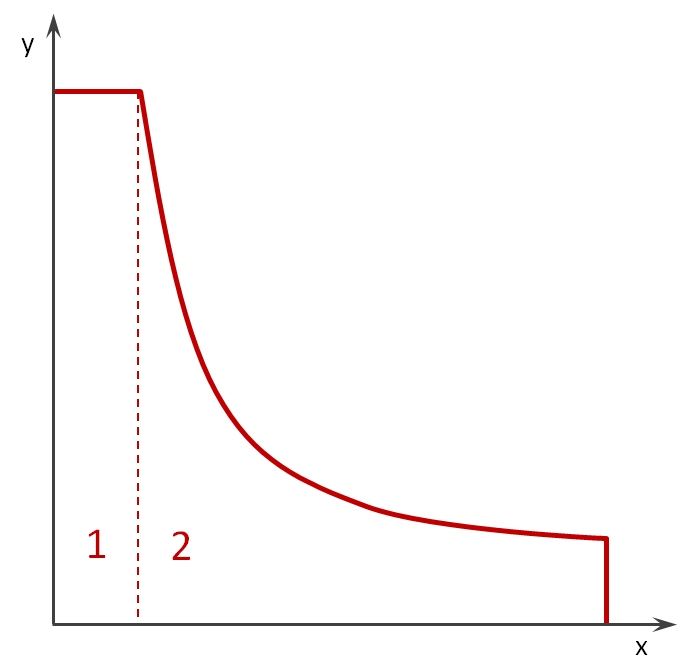
Skizze zur Berechnung möglicher Paarungen bei Gleichverteilung
Um die kumulative Wahrscheinlichkeitsfunktion zu berechnen, werden wir einfach annehmen, dass die Wahrscheinlichkeit für alle passenden Paarungen jeweils 1/100 sein wird. Wie die oben gezeigte Skizze illustriert, ist die Hyperbel wegen der Beschränkung der Werte gestutzt. In unserem Fall geschieht dies sobald eine der Zufallsvariablen größer als 10 wird. Wenn wir uns an den Grundgedanken aus dem vorangehenden Abschnitt erinnern, müssen wir nur über die Wahrscheinlichkeiten unterhalb des gezeigten Graphen integrieren. Dazu teilen wir die Funktion in zwei Teile. Das tun wir dort, wo die Grenze von



Wir berechnen alle Werte mit 
= \int\limits_{0}^{\frac{z}{10}} \int\limits_{0}^{10} g_{x,y}\big(x,y \big) \, dy \, dx + \int\limits_{\frac{z}{10}}^{10} \int\limits_{0}^{\frac{z}{x}} g_{x,y}\big(x,y \big) \, dy \, dx")
= \int\limits_{0}^{\frac{z}{10}} \int\limits_{0}^{10} \frac{1}{100} \, dy \, dx + \int\limits_{\frac{z}{10}}^{10} \int\limits_{0}^{\frac{z}{x}} \frac{1}{100} \, dy \, dx = \frac{z}{100} + \frac{z}{100} \int\limits_{\frac{z}{10}}^{10} \frac{1}{x} \, dx")
![\displaystyle F_{z}\big(z\big)=\frac{z}{100} + \frac{z}{100} \Big[ ln(x) \Big ]_{\frac{z}{10}}^{10}=\frac{z}{100} \Big(1+2\cdot ln(10)-ln(z)\Big)](http://s0.wp.com/latex.php?latex=%5Cdisplaystyle+F_%7Bz%7D%5Cbig%28z%5Cbig%29%3D%5Cfrac%7Bz%7D%7B100%7D+%2B+%5Cfrac%7Bz%7D%7B100%7D+%5CBig%5B+ln%28x%29+%5CBig+%5D_%7B%5Cfrac%7Bz%7D%7B10%7D%7D%5E%7B10%7D%3D%5Cfrac%7Bz%7D%7B100%7D+%5CBig%281%2B2%5Ccdot+ln%2810%29-ln%28z%29%5CBig%29&bg=ffffff&fg=000000&s=0 "\displaystyle F_{z}\big(z\big)=\frac{z}{100} + \frac{z}{100} \Big[ ln(x) \Big ]_{\frac{z}{10}}^{10}=\frac{z}{100} \Big(1+2\cdot ln(10)-ln(z)\Big)")
Nun differenzieren wir noch schnell nach 
\big)}{dz}=\frac{2\cdot ln(10)-ln(z)}{100}=g_{z}(z)")
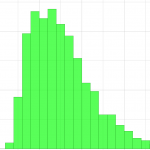
Und so sieht unsere Wahrscheinlichkeitsdichtefunktion aus:
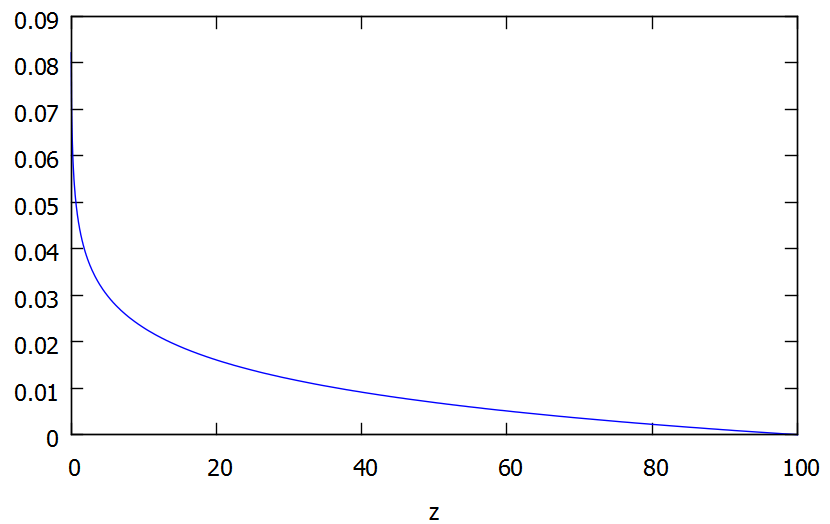
Wahrscheinlichkeitsdichtefunktion des Produktes zweier gleichverteilter Zufallsvariablen
Ausblick
Wie wir gesehen haben, kann die Berechnung einer konkreten Verteilung zweier Zufallsvariablen einen gewissen Aufwand fordern. Mit etwas Geschick können wir so aber verschiedene praktische Aufgaben lösen. Zum Beispiel könnte ja die Verteilung der Besucher eines Parkplatzes sowie die Verteilung der PKW-Breite bekannt sein. Dann is est möglich, eine Aussage über den benötigten Platz auf dem Parkplatz zu treffen. Prinzpiell können wir auch mehr als zwei Variablen miteinander verknüpfen, denn schließlich gilt ja  \cdot C")

 (3 Stimmen, Durchnschnitt: 4,00 von 5)
(3 Stimmen, Durchnschnitt: 4,00 von 5)




Schreibe einen Kommentar